



Photo by Priscilla Du Preez on Unsplash
Part 3: Looping through Multiple Google Scholar Authors in your Fabric data data pipeline
Process and fetch information for multiple authors from a REST API


In this article, we will guide you through the process of looping through multiple authors in Google Scholar data ingestion into Fabric. By following these steps, you will be able to efficiently retrieve data for multiple authors and save it in a structured manner. Let's dive in!
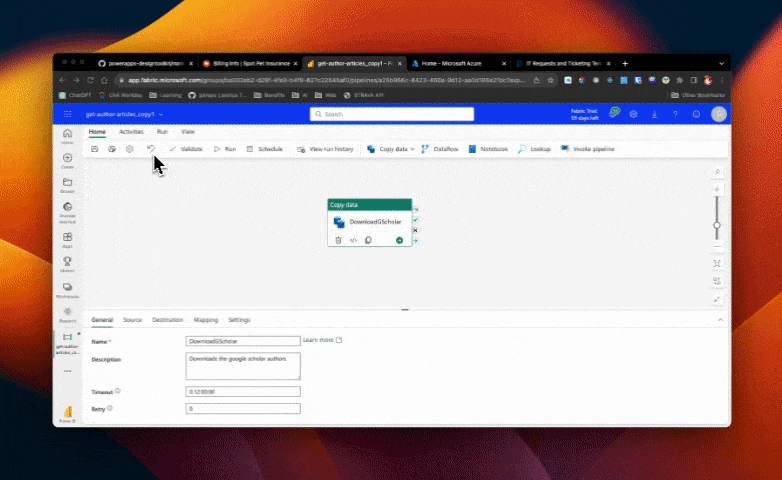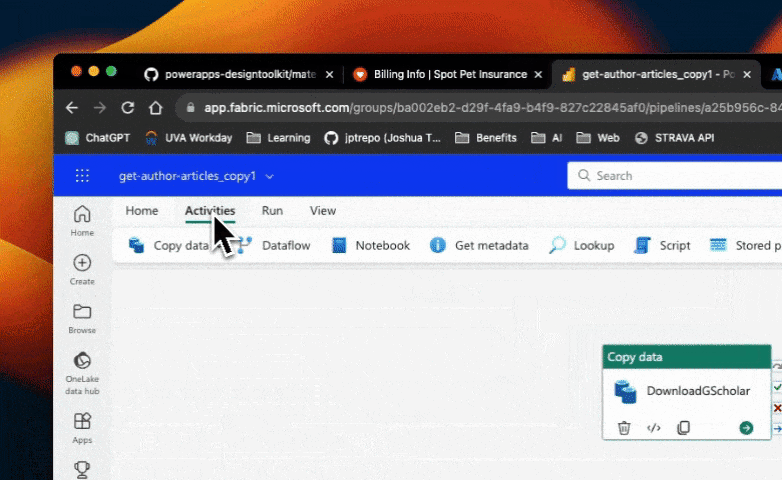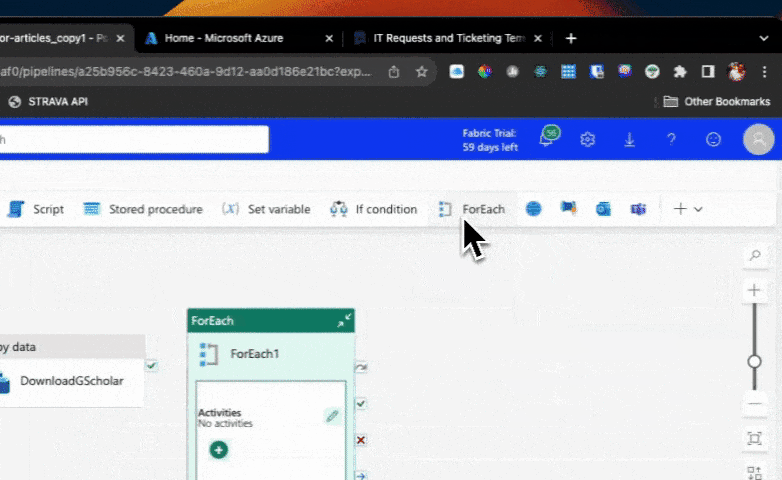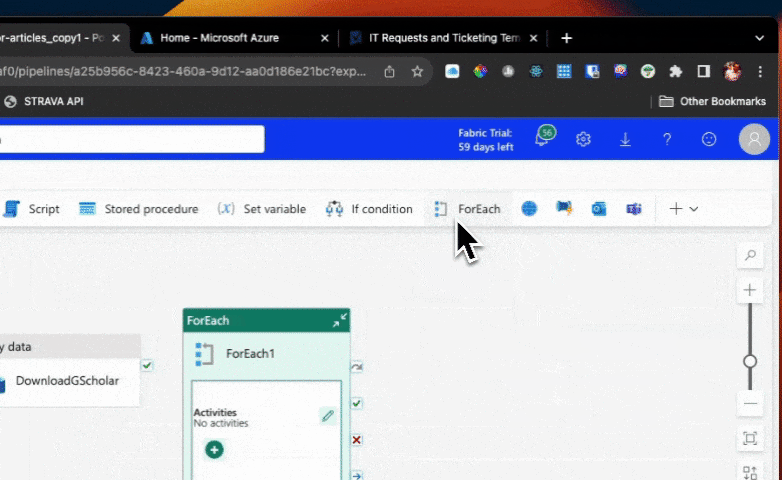
Step 1: Adding the "For Each" Activity
The first step is to add the "For Each" activity to your pipeline. This activity can be found in the activities tab. Simply click on it to add it to your pipeline. This activity will allow us to loop through a list of authors and perform actions on each author individually.
Step 2: Copying the Copy Activity
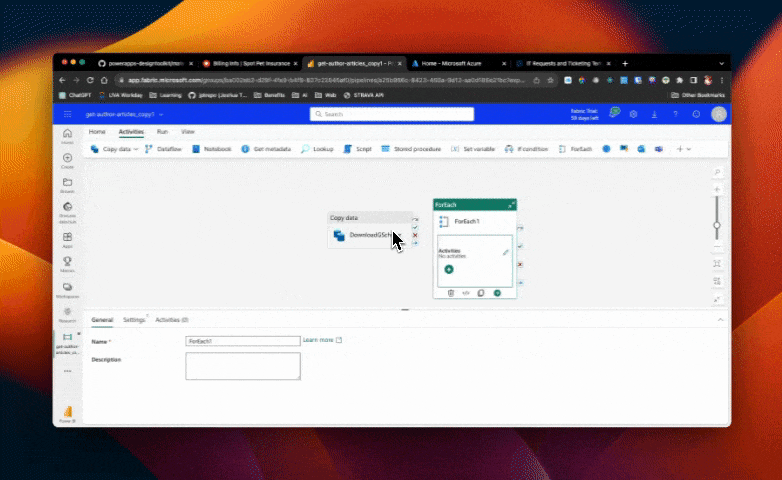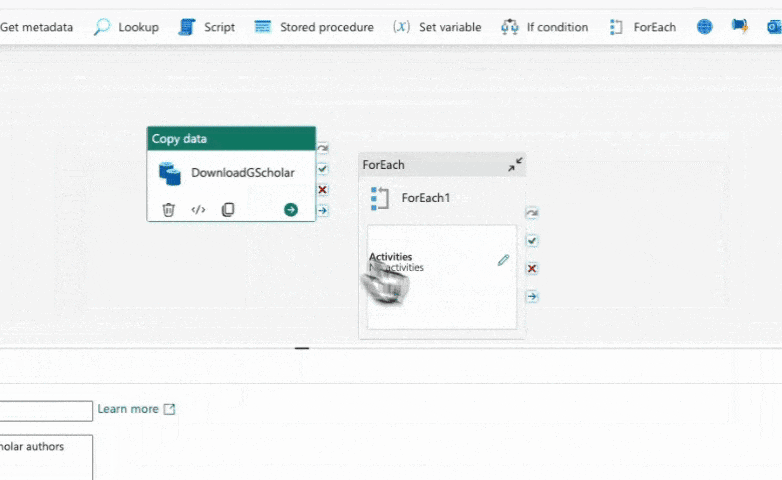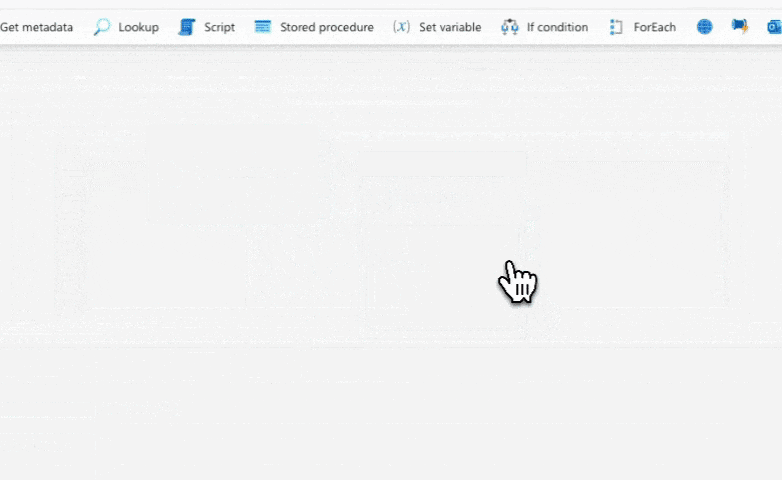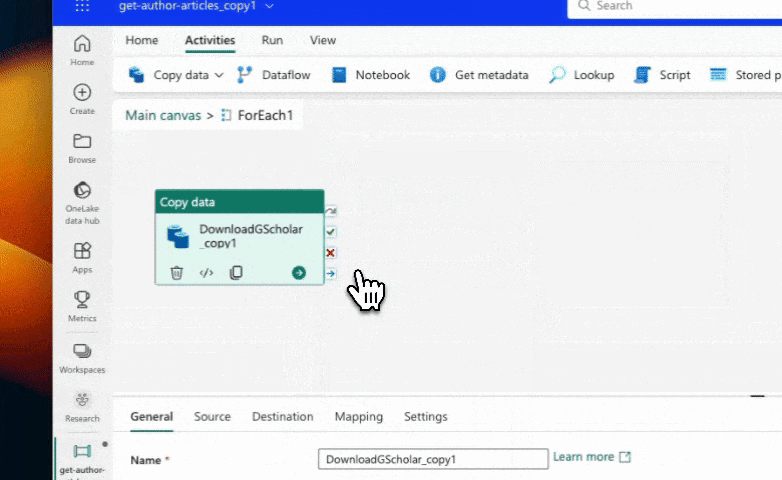
Next, we need to copy the existing copy activity. Locate the copy activity in your pipeline and right-click on it. Then, select the "Copy" option. We will be using this copied activity inside the "For Each" activity.
Then we paste the copied activity inside the "For Each" activity. To do this, click on the pencil icon within the "For Each" activity. This will open a new canvas where we can edit the activities within the loop. Simply paste the copied activity here.
Step 3: Moving from a single author to a list of authors
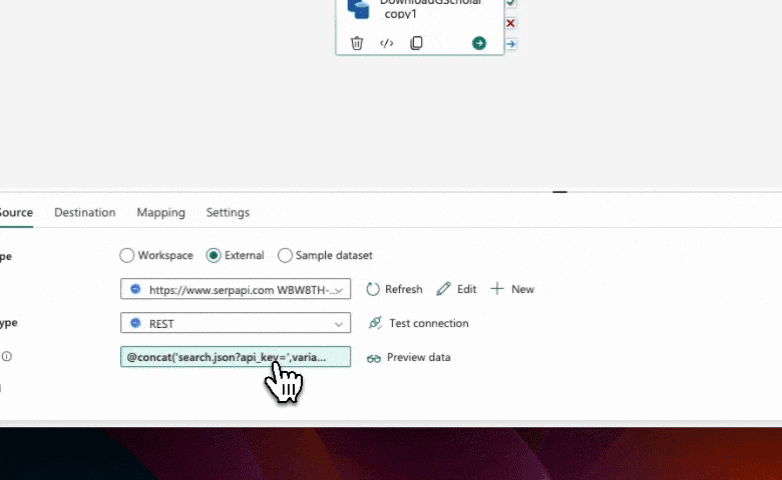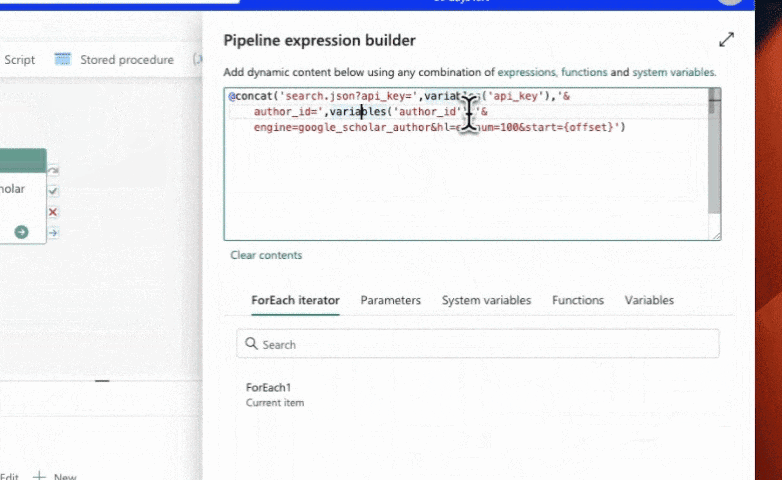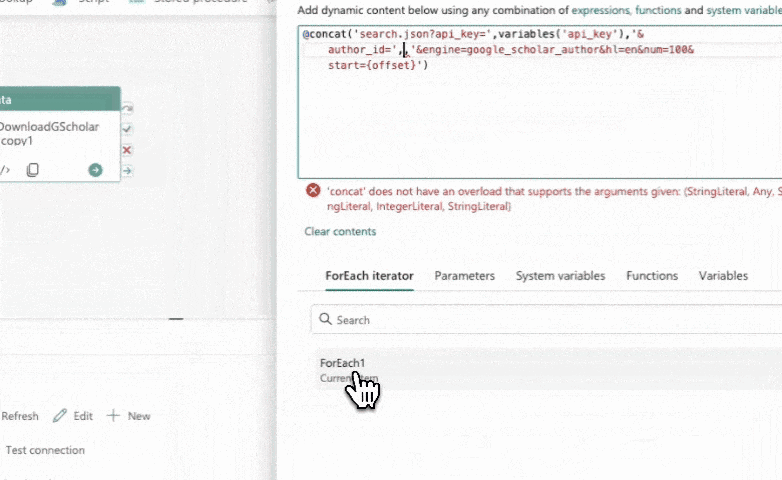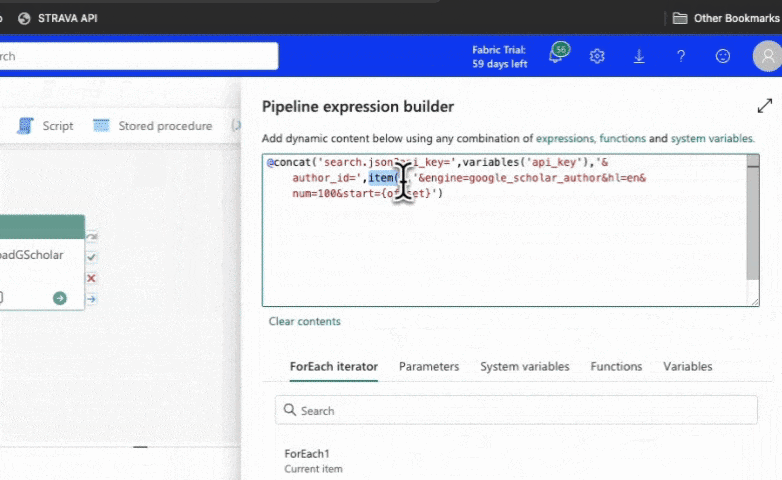
Before we move on to the last step, let's take a moment to understand the concept behind this process. We have a "For Each" activity that will loop through a list of authors. To provide this list, we can use an array. You can create an array of author IDs separated by commas and quotes like so: ["author_id_1", "author_id_2", "author_id_3"].
Kind of like working through rows in an Excel file where each row is a different author, this array can be used by the For Each activity to process and download data for each author. Any activity you put in this for each activity will occur for every author in the loop.
We can store this list in a variable to reference later.
Step 4: Modifying the Copy Activity
At this point, let's run the pipeline and see what happens.
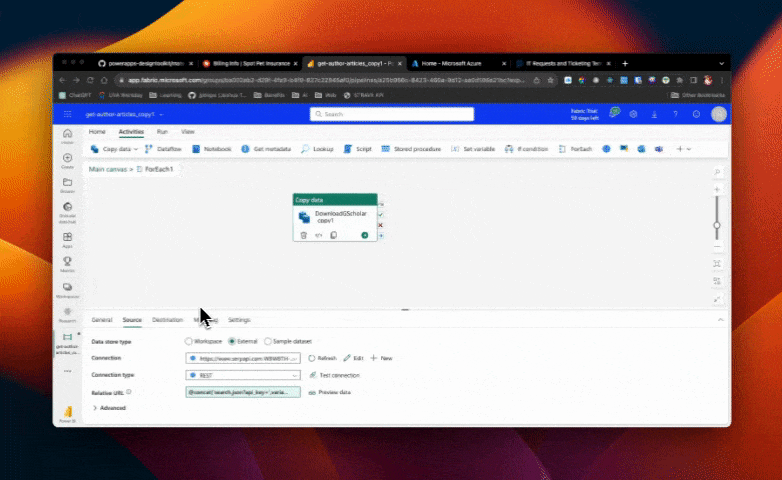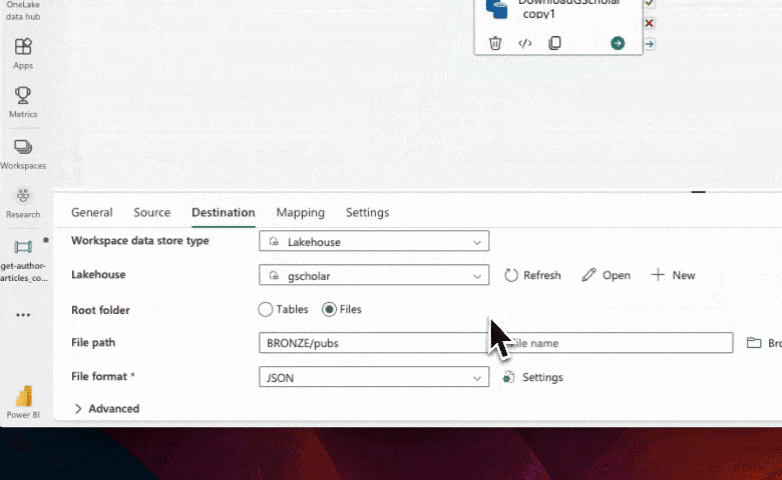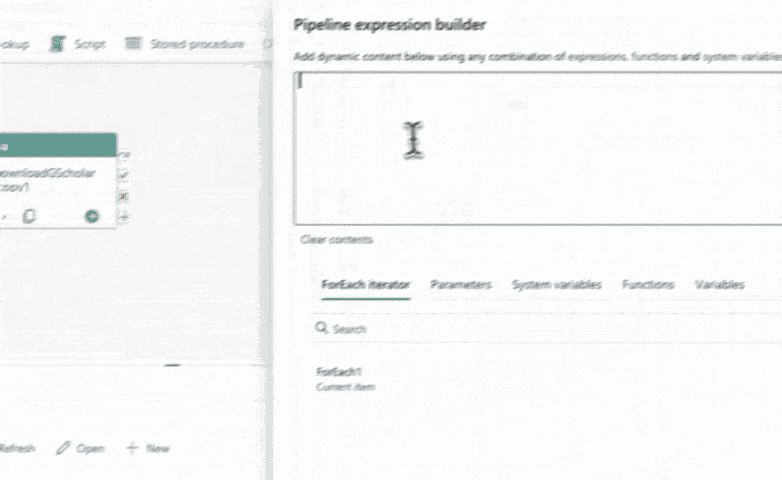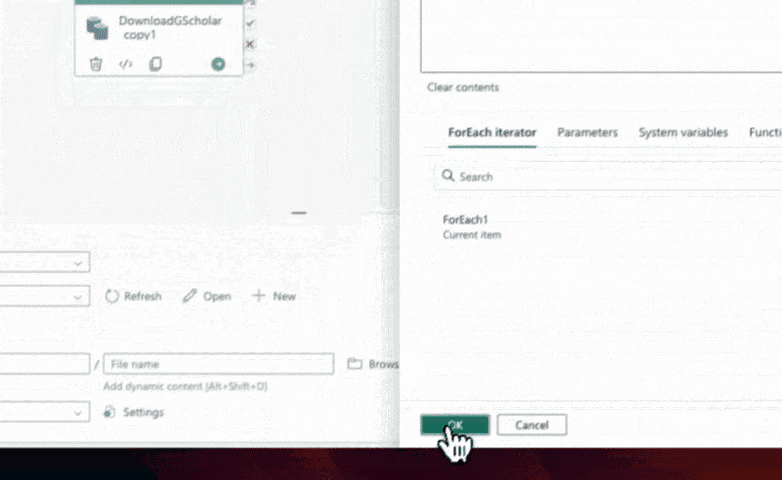
In the copy data activity, we need to ensure that we are passing the current author ID to the URL field. Currently, it is passing every author ID every time, which obviously causes failures. Using our Excel analogy above, this would be like pasting the entire column of author IDs into the URL field.
To fix this, we can use the item() "For Each" iterator to get the current author ID. This is like getting the CURRENT row's author ID only and merging it into our URL (THEN going to the URL). Simply click on the merge tag that the iterator provides, and it will automatically insert the correct expression: item(). Save the changes and run the pipeline again.
Step 5: Saving Files with Author ID
Ok that worked, but the file name is ugly and saved in such a way that any subsequent download will duplicate data for the author. Instead, let's focus on saving the retrieved data with the name of the current author. This will allow us to easily identify and update the data for each author in future runs (via overwriting prior data - which isn't a big deal in this case since we will get all the same data and any additional). To do this, we need to modify the destination file path in the copy data activity.
Locate the copy data activity and navigate to the destination tab. In the file path field, set the file name to be the concatenation of the current author ID and a file extension (e.g., ".json"). This can be achieved using the concat function in the pipeline Expression Builder. Ensure that the file path is set to your desired location and save the changes.
By following these steps, you will now have the data saved with the name of the current author. This will allow you to easily manage and update the data for each author in the future.
Conclusion
Congratulations! You have successfully learned how to loop through multiple authors in Google Scholar data ingestion into Fabric. By implementing these steps, you can efficiently retrieve and save data for multiple authors in a structured manner. Plus, now that they are all saving in the lakehouse, we are beginning to set the stage for future activities (save to delta tables, move to SQL, etc).
We still have a problem, though, caused by result paging. In the next video, we will address the issue of paging in Google Scholar and explore how to retrieve data from multiple pages for one author. Some researchers publish A LOT. Stay tuned to review this more advanced technique!
Remember, practice makes perfect. Keep experimenting and exploring new possibilities with Fabric to enhance your data ingestion process. Happy looping!