

Part 4: Turning the Page on Data Pipelines
Using API pagination in data factory




Photo by Nathan McDine on Unsplash
Table of contents
Turning the Page on Data Pipelines
In the world of data pipelines, there comes a time when we need to address the issue of paging. Paging refers to the process of retrieving data in chunks or pages, rather than all at once. This is particularly relevant when dealing with large datasets or when accessing APIs that have pagination features. In this article, we will explore the concept of paging in data pipelines and discuss how to implement it effectively.
Understanding Paging
When working with APIs or web pages that have pagination, it is common to encounter limitations on the number of records or results that can be displayed on a single page. For example, when using Google Scholar, only the first 20 results are shown by default, and the user has to manually click "show more" to view additional results. Similarly, in our data pipeline, we may encounter APIs that return data in pages, with each page containing a limited number of records.
The Challenge of Paging in Data Pipelines
Let's take a closer look at a specific scenario in our data pipeline. Suppose we are pulling data from an API that provides information about authors and their publications. We have successfully retrieved the profile information, cited by data, and publications for a particular author, let's say Gene Hunt. However, we realize that we are only getting the data from the first page of results. To access the subsequent pages and retrieve all the articles, we need to implement paging in our data pipeline.
Implementing Paging in Data Pipelines
To address the challenge of paging in our data pipeline, we can leverage the built-in pagination functions available in the copy activity. By configuring the pagination rules, we can instruct the pipeline to retrieve data from subsequent pages until all the desired records are obtained.
Step 1: Identifying Pagination Elements
Before we can implement paging, we need to identify the pagination elements in the API response. In the case of the SERP API, we can find the pagination information by examining the response body. Specifically, we are interested in the "next" element within the SERP API pagination.
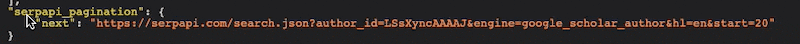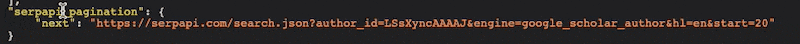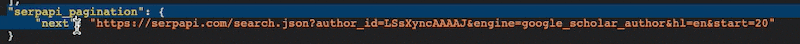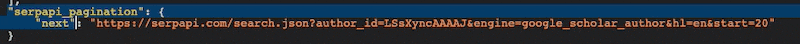
Step 2: Configuring Pagination Rules
Once we have identified the pagination elements, we can configure the pagination rules in the copy activity. By clicking on the "for each" activity and then the copy activity, we can access the pagination rules in the "Source" tab. With some APIs, we could use the "absolute URL" option since the SERP API provides the full URL for the next page in the body of the response, as shown above.
However, while this SHOULD work by just pointing the AbsoluteURL rule body pagination rule at serpapi_pagination.next, it doesn’t for us because we need the API key. And that key is not in the next URL. And using a dynamic expression to append it doesn’t seem to work (feel free to correct me in the comments!!).
Step 2 redux: Setting Pagination Values
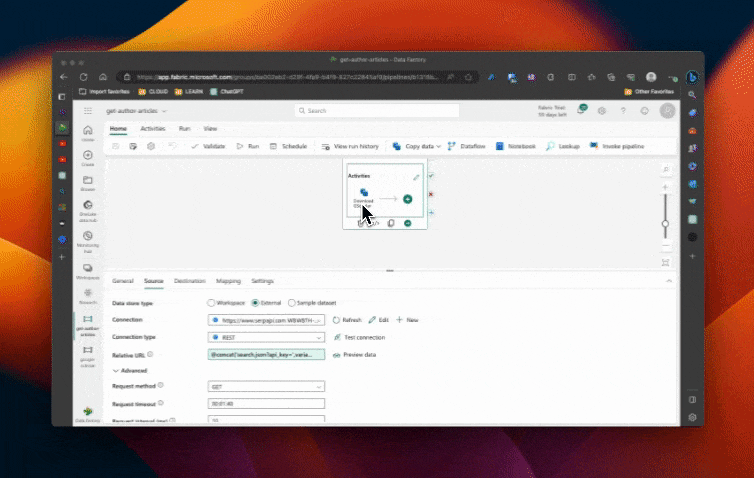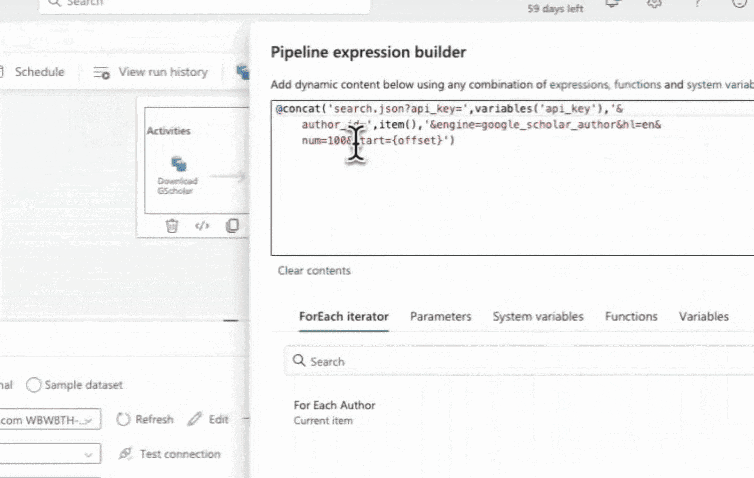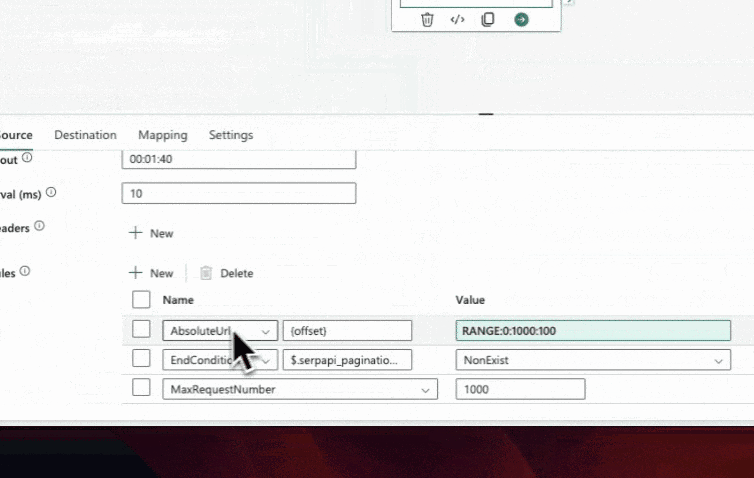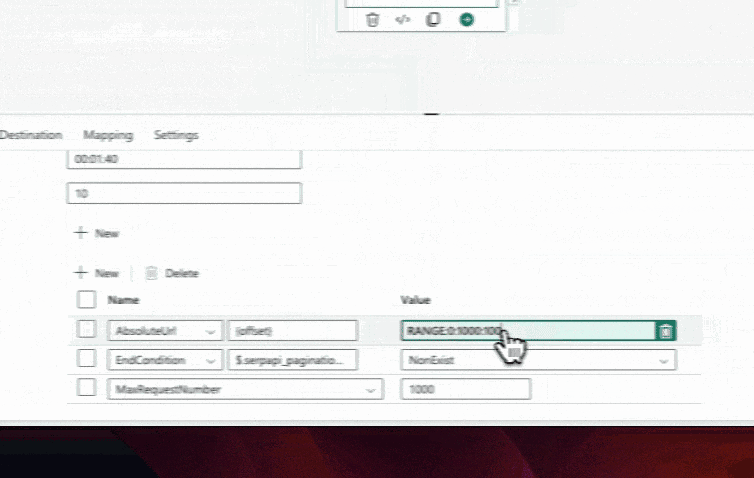
For us, we will dynamically handle the pagination by placing a variable placeholder in the relative url for the start parameter. By using this variable, we can ensure that the pipeline retrieves data from multiple pages if they exist. Additionally, we can use the range function to specify the range of start values, such as incrementing by 100 for each page, starting at 0 and incrementing to 1000.
Step 3: Handling Pagination Exceptions
To download the full collection of articles and prevent endless looping when using the range method shown above, we can add conditions to check if the pagination element exists and set a maximum number of requests as a fail-safe measure. If there is no pagination element, it means you are at or beyond the last page and our setting then stops the pagination loop.
Step 4: Running the Data Pipeline
Once we have configured the pagination rules, we can run the data pipeline and monitor the progress. By examining the file sizes of the retrieved data, we can verify if the pipeline successfully retrieved data from multiple pages. In this case, we SHOULD expect a wide range of file sizes.
And we do. Yay!
Conclusion
Implementing paging in data pipelines is crucial when dealing with APIs or web pages that have pagination features to ensure you have a complete data set. By configuring pagination rules and handling exceptions, we can ensure that our data pipeline retrieves all the desired records from subsequent pages. With the ability to effectively handle paging, we can unlock the full potential of our data pipelines and access comprehensive datasets for analysis and insights.
In our next few videos, we will employ the notebook feature of Fabric to process our downloaded data and get it into Delta Lake tables in our silver layer. We may also look at how we could have made this API download routine easier using a notebook, to begin with, but why the data pipeline orchestration capability is still important.