



Photo by David Clode on Unsplash
Part 5: Introducing Fabric Notebooks & Python to our Lakehouse GScholar project
Python Joins Our Lakehouse GScholar Journey


Welcome to video five! In this video, we will be introducing notebooks, their usage in Microsoft Fabric, and their usefulness in the data prep process. You might wonder why we don't just use notebooks from the beginning and skip all the data pipeline ClickOps? That would be a valid way to go about it and one I would likely do. However, that wouldn't give us as much of an overview now would it?
What are we going to do with this here notebook, you ask?
If you open up one of the authors with multiple pages worth of articles, you'll notice that for each page of articles, we copied the author information, citation stats, publications, and other relevant data for each page. Only the articles, though, differed from page to page. We want to merge all these articles together into one document, so we have all the articles in one place, along with the author and citation stats.
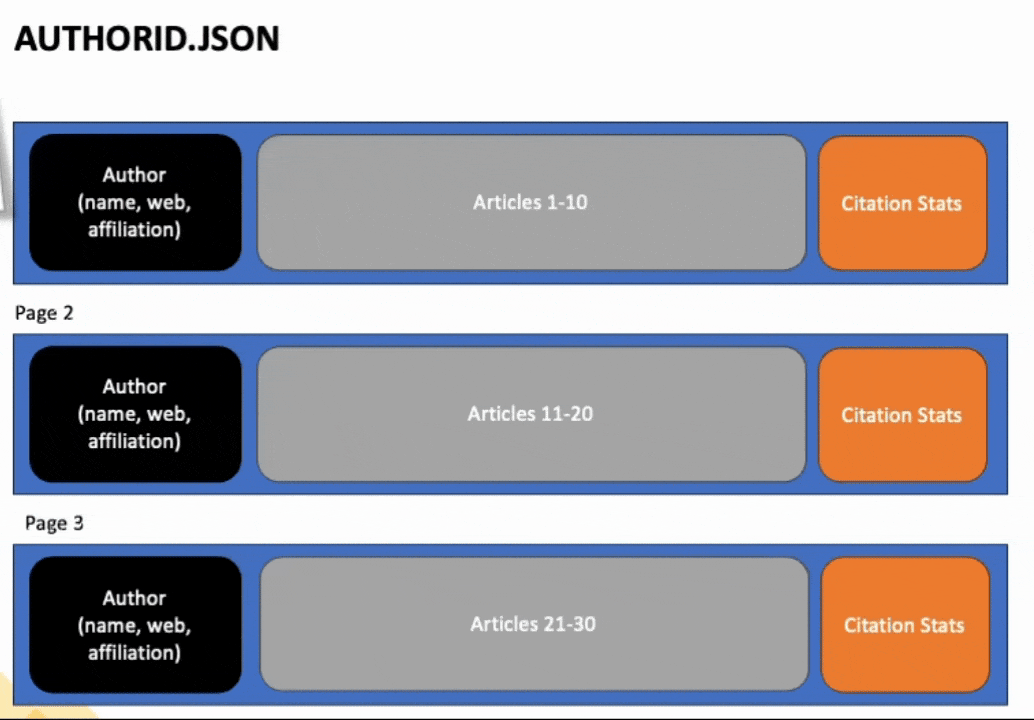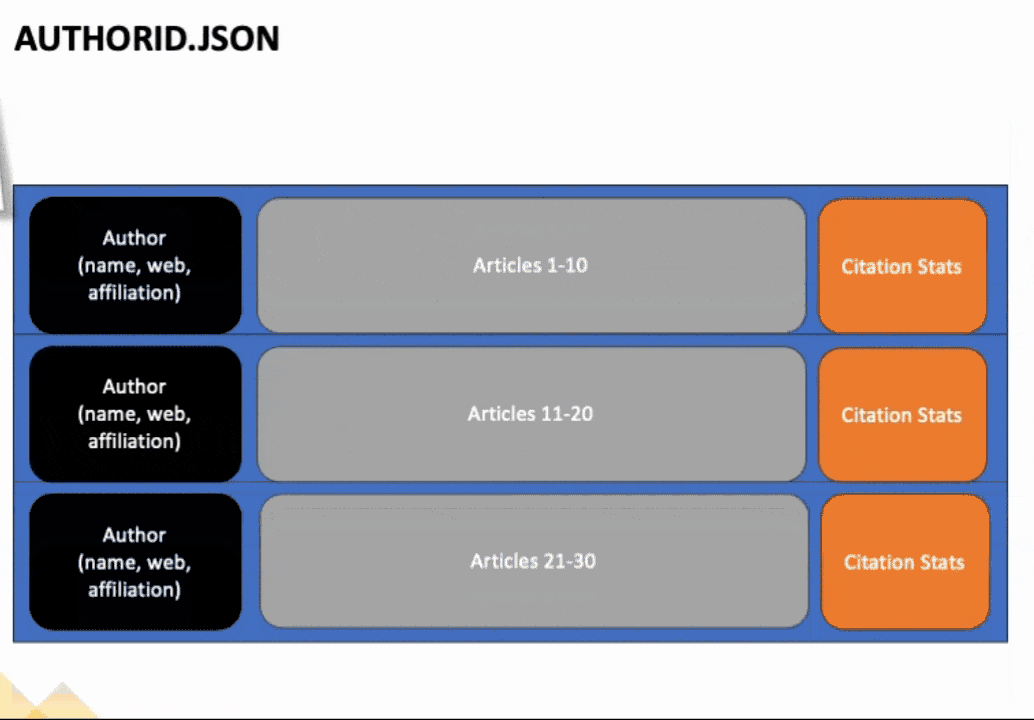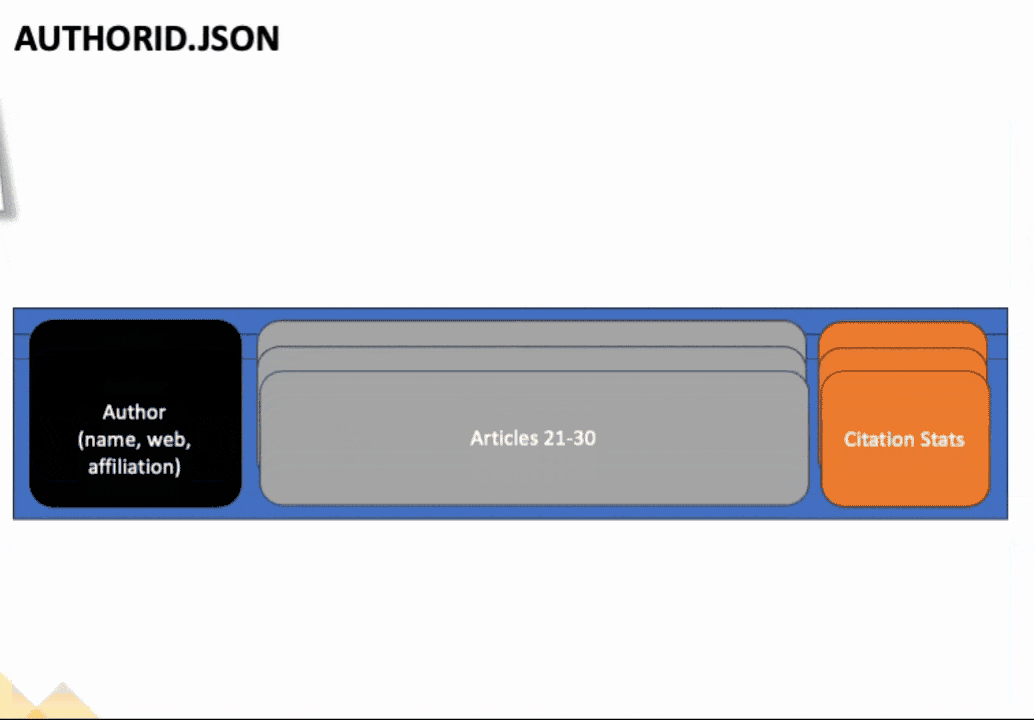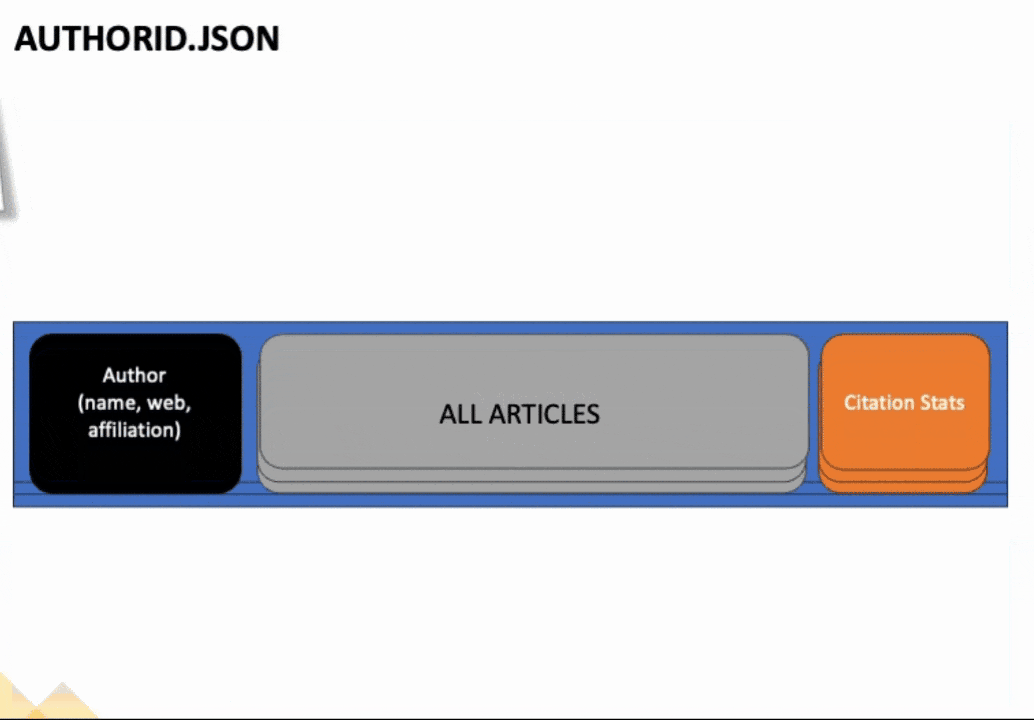
To achieve this, we will explore the fabric notebook environment. If you have used Jupyter notebooks before, you will feel right at home with Fabric notebooks. There are a few unique features in the notebook environment of which you should be aware (that makes life easier!!).
Lake House Explorer
By default, on the left side, we have our lakehouse explorer mounted to the notebook environment. This allows us to easily access any files that we have downloaded into OneLake.
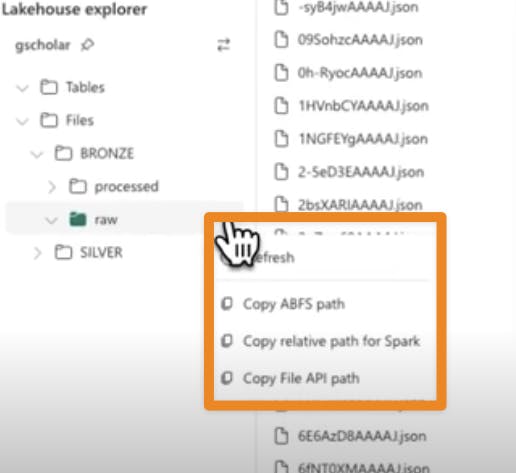
We also have these handy shortcuts all over the notebook interface that lets us easily copy file paths and references into our notebook code. Super helpful!
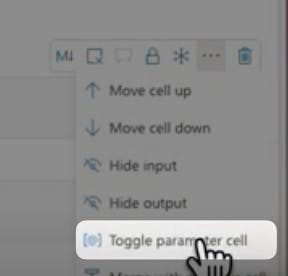
Parameters in Microsoft Fabric Notebooks
Next, we look at parameters. Parameters allow us to create variables and pass data into our notebook from other activities, such as the data pipeline. To create a parameter variable, we make a code cell and mark it as a parameter cell. This allows us to create an author ID variable that we can access from outside of the notebook.
Loading and Manipulating Data in Microsoft Fabric Notebooks
In the rest of the video, we use our notebook to grab and reshape the data how we want. We grab the author from the first page, the citation statistics from the first page, combine the articles from all pages into one object, and move the output to a processed folder. We will come back to this processed folder in a future video to make our delta tables and silver layer!!!
Conclusion
In the next few videos, we will work on starting to build out our silver layer and setting the stage for a scheduled automation by putting our notebook into our automated pipeline.
Isn't this fun?